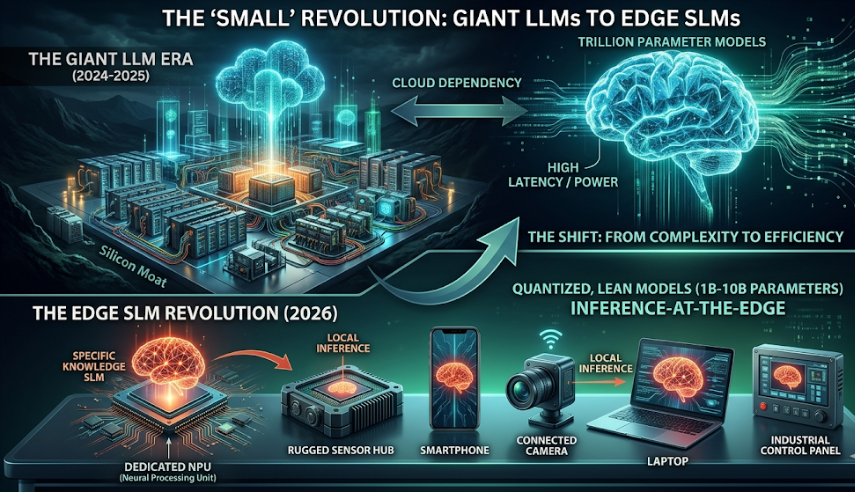
The narrative of 2024 and 2025 was dominated by “bigger is better.” We watched as parameter counts climbed into the trillions and data centers grew into the size of small cities. But as we move through 2026, the pendulum is swinging back.
We are officially entering the era of the Small Language Model (SLM).
The industry is realizing that for the majority of enterprise and consumer applications, we don’t need a digital “god-in-a-box” that knows everything about history and art. We need specialized, lean, and hyper-efficient intelligence that can live where the data is actually born at the edge.
1. The Intelligence “Diet”: Why Smaller is Smarter
SLMs (typically defined as models with 1B to 10B parameters) are no longer “lite” versions of their bigger siblings. Thanks to breakthroughs in quantization and knowledge distillation, a 7B parameter model today can often outperform a 70B model from two years ago on specific tasks.
- Efficiency: Running a model on a local NPU (Neural Processing Unit) consumes milliwatts, whereas a cloud call to a frontier model consumes significant energy and bandwidth.
- Speed: Zero-latency interaction is only possible when the “brain” is on the device.
2. The Hardware Flip: NPUs as the New Standard
The hardware landscape has shifted to meet this demand. We are seeing a “silicon specialization” where CPUs handle the logic, GPUs handle the graphics, and dedicated NPUs handle the persistent AI background tasks.
This hardware-software synergy allows for “always-on” AI that doesn’t drain a battery in twenty minutes. It’s the difference between a device that has AI and a device that is AI.
3. Privacy: The Ultimate Feature
In the “Big LLM” era, data privacy was a constant negotiation. To get the best results, you had to send your data to someone else’s server.
Edge SLMs change the equation. When the model lives on your smartphone, your laptop, or your factory floor sensors, the data never leaves the local environment. This is the “Silicon Vault” approach—intelligence without exposure.
4. The Transition: From “Cloud-First” to “Inference-Local”
We are seeing a new architectural pattern emerge:
- The Cloud is for training and heavy, multi-modal reasoning.
- The Edge is for execution, personalization, and real-time inference.
5. The “Energy Wall”: Why Small is the Only Way Forward
The hidden driver behind the SLM movement isn’t just speed—it’s thermal and power constraints.
- The Reality: Data centers are hitting a “power wall” where the grid literally cannot supply more electricity.
- The Solution: By moving inference to the edge, we distribute the energy load across billions of devices. SLMs optimized for INT8 or FP8 precision allow for massive “intelligence per watt” gains that giant models simply can’t match.
6. Real-Time Personalization without the Data Breach
The biggest weakness of a giant, static LLM is that it doesn’t know you.
- Local Context: An SLM running on a local device can ingest your specific files, emails, and sensor data in real-time to provide hyper-relevant assistance.
- On-Device RAG: Implementing Retrieval-Augmented Generation (RAG) locally means your “Silicon Fingerprint” stays on your hardware, making your AI assistant actually useful without being a privacy liability.
7. Hardware-Aware Software: The New Engineering Frontier
We are moving away from “write once, run anywhere.”
- The Shift: Software engineers are now working closer to the metal. To make an SLM truly “small,” developers are using techniques like pruning (removing unnecessary neurons) and weight sharing.
- Compiler Innovation: Tools that automatically optimize a model for a specific NPU architecture are becoming the “secret sauce” of the most successful hardware-software integrated products of 2026.
8. The Rise of the “Micro-Agent”
Instead of one giant model trying to do everything, we are seeing the rise of Federated Micro-Agents.
- Specialization: Your phone might run three different 1B-parameter models simultaneously—one for voice processing, one for visual recognition, and one for predictive text.
- Orchestration: The hardware’s role is to act as an orchestrator, spinning these models up and down in milliseconds based on the user’s immediate need.
The future of hardware isn’t just about building bigger pipes to the cloud; it’s about building smarter reservoirs at the edge. The “Small” Revolution is proving that in the world of silicon and strategy, efficiency is the ultimate sophisticated scale.
